


RAG Evaluation with LLM-as-a-Judge + Synthetic Dataset Creation
Forget Custom Human QA Pairs

RAG(Retrievel-Augmented Generation) acts as an internal query tool that utilizes LLMs to retrieve information from a “knowledge” base.
Evaluating an LLM is simple: during training, LLMs utilize human feedback(RLHF) to assign weights to particular model outputs based on categories, such as semantics, toxicity, and hostility. The LLM adjusts and creates more alike outputs.
With RAG-based systems, however, the success of such systems depends on the LLM’s ability to extract product-useful information. Therefore, the evaluation of RAG cannot depend on benchmarks or semantics.
Solution? Custom evaluation dataset + LLM-as-a-judge.
➡️ It turns out, we can use LLMs to help us all along the way!

Here’s What You’ll Learn in THIS Article:
System Design of a Complex RAG System
How to Implement an LLM-as-a-Judge RAG: Complete Code Walkthrough
1 — Let’s Start: System Design of a Complex RAG System
RAG is a popular approach to address the issue of a powerful LLM not being aware of specific content due to said content not being in its training data, or hallucinating even when it has seen it before. Such specific content may be proprietary, sensitive, or, as in this example, recent and updated often.
Here’s how we got here:
LLMs trained on large amounts of data achieve broad-spectrum general knowledge. However, prompting an LLM to generate a completion that requires knowledge that was not included in its training data is inefficient.
In 2020, Lewis et al. proposed a more flexible technique called Retrieval-Augmented Generation (RAG) in the paper Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks [1]. In this paper, the researchers combined a generative model with a retriever module to provide additional information from an external knowledge source that can be updated more easily.

Over the past few years, RAG systems have evolved from Naive RAG to Advanced RAG and Modular RAG. This evolution has occurred to address certain limitations around performance, cost, and efficiency.

How to Implement an LLM-as-a-Judge RAG: Complete Code Walkthrough
For our evaluation pipeline, we will need to:
How to use the LLM to Generate This Synthetic Evaluation Dataset
Setup LLM Critique Agents
Build & Test the RAG system
Find code here.
Step 1 — How to use the LLM to Generate This Synthetic Evaluation Dataset
We first build a synthetic dataset of questions and associated contexts. The method is to get elements from our knowledge base and ask an LLM to generate questions based on these documents.

The following code generation results in a data frame of following structure: (context, question, answer, source_doc)

Step 2 — Setup LLM Critique Agents
The questions generated by the previous agent can have many flaws: we should do a quality check before validating these questions.
We thus build critique agents that will rate each question on several criteria, given in this paper:
Groundedness: can the question be answered from the given context?
Relevance: is the question relevant to users? For instance,
"What is the date when transformers 4.29.1 was released?"is not relevant for ML practitioners.Stand-alone: is the question understandable free of any context, for someone with domain knowledge/Internet access? The opposite of this would be
What is the function used in this article?for a question generated from a specific blog article.

After setting up the LLM critics, you should filter out the bad outputs.
Step 3 — Build and Test the RAG System
3.1. — Preprocessing documents to build our vector database
In this part, we split the documents from our knowledge base into smaller chunks: these will be the snippets that are picked by the Retriever, to then be ingested by the Reader LLM as supporting elements for its answer.
The goal is to build semantically relevant snippets: not too small to be sufficient for supporting an answer, and not too large too avoid diluting individual ideas.
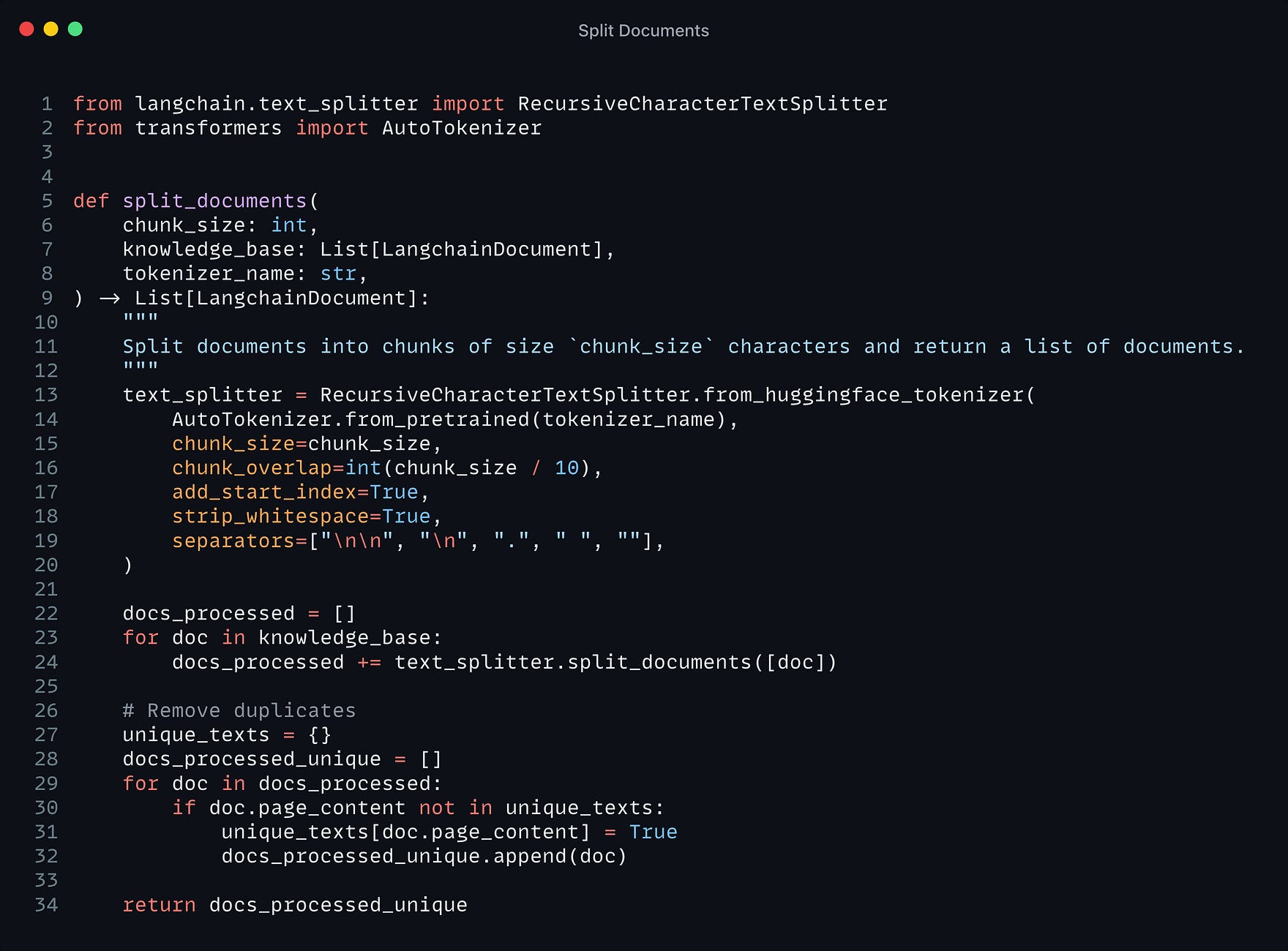
3.2. — Build the RAG Retriever -> Embeddings 🗂️
The retriever acts like an internal search engine: given the user query, it returns the most relevant documents from your knowledge base.
For the knowledge base, we use Langchain vector databases since it offers a convenient FAISS index and allows us to keep document metadata throughout the processing.
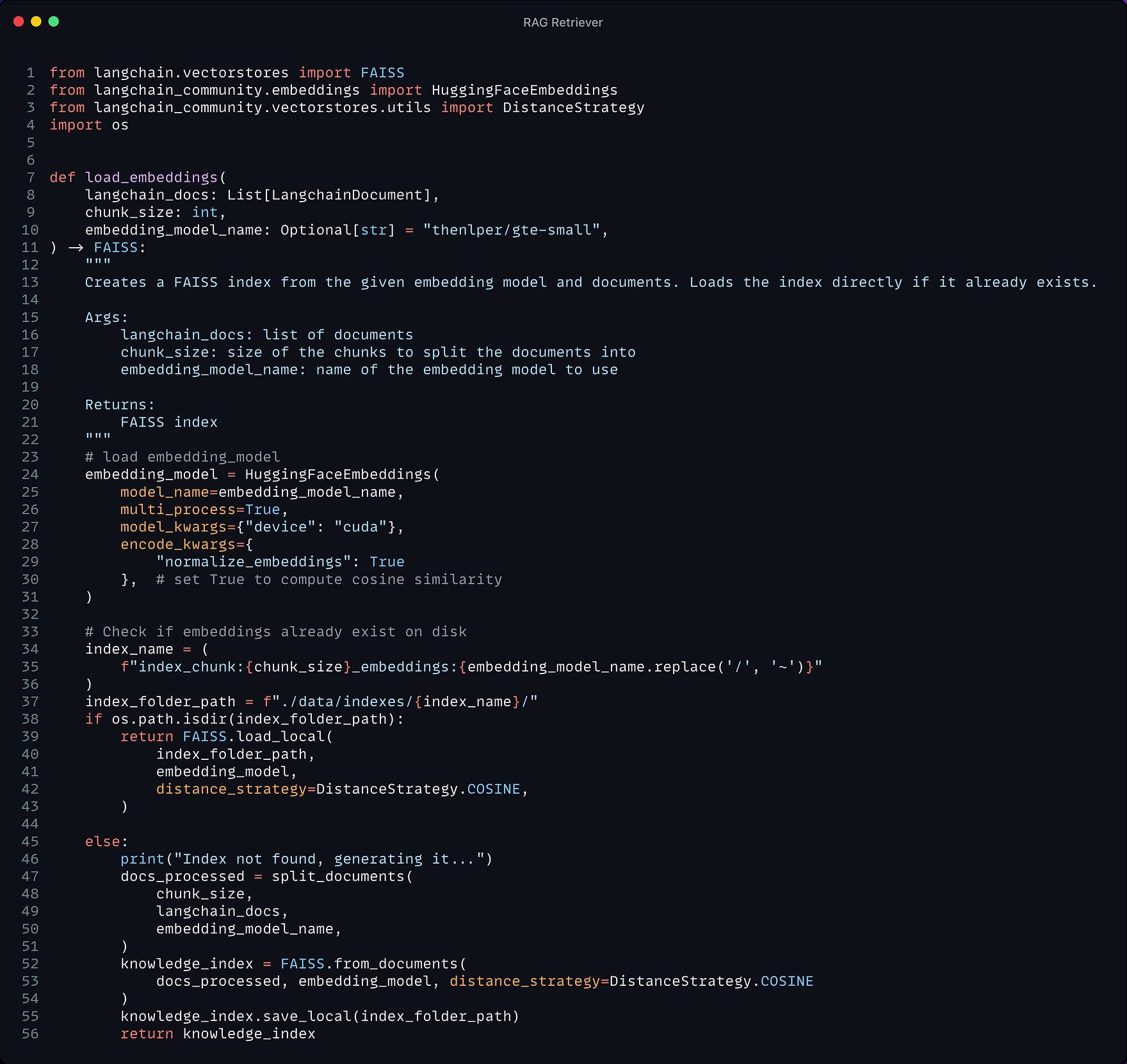
3.3 — Build the RAG Reader
In this part, the LLM Reader reads the retrieved documents to formulate its answer.

3.4 — We have the Evaluation Dataset. We have the RAG System. Let’s Evaluate.
The RAG system and the evaluation datasets are now ready. The last step is to judge the RAG system’s output on this evaluation dataset.
💡 In the evaluation prompt, we give a detailed description of each metric on a scale 1–5, as is done in Prometheus’s prompt template: this helps the model ground its metric precisely. If instead, you give the judge LLM a vague scale to work with, the outputs will not be consistent enough between different examples.
💡 Again, prompting the LLM to output rationale before giving its final score gives it more tokens to help it formalize and elaborate a judgment.

Conclusion
In this article, I elaborated on how you can build your own RAG system without building your evaluation dataset to measure LLM performance. We utilized 2 key “power play automations”:
Using LLMs to generate a synthetic QA evaluation dataset.
Using LLMs-as-a-judge to formulate answer accuracy/semantics.
Here’s what I’ve learned when studying this:
RAG is a very powerful method to increase your system’s performance via an internal query engine driven by natural language.
You should try multiple combinations of pretrained LLM-as-a-judge/prompt templates/RAG models to arrive at best accuracy.
Be careful which model you use as a judge. Your system depends on it.
Enjoyed This Story?
Thanks for getting to the end of this article. My name is Tim, I love to elaborate ML research papers or ML applications emphasizing business use cases! Get in touch!
Subscribe for free to get notified when I publish a new story.
Get an email whenever Tim Cvetko publishes.
Get an email whenever Tim Cvetko publishes. By signing up, you will create a Medium account if you don’t already have…medium.com